

Introduction
I have spent years examining how modern AI systems behave once they leave research papers and enter real-world use. One pattern keeps resurfacing across evaluations, product deployments, and benchmark reviews. Even the most advanced models remain inconsistent when asked to reason across long contexts, track meaning over time, or apply logic reliably. This article explores Why AI Models Struggle With Context and Reasoning by looking beneath the surface of fluent text generation and into the design choices that shape model behavior.
Within the first moments of interaction, users notice something subtle. AI can summarize documents, answer questions, and generate convincing explanations. Yet it often forgets earlier constraints, contradicts itself, or misses implications that feel obvious to humans. This gap between surface competence and deeper understanding drives confusion about what these systems actually know.
The search intent behind this topic is clear. Readers want to understand whether these failures are bugs, training issues, or fundamental limitations. The answer is not a single cause. Context handling and reasoning depend on architecture, data structure, evaluation methods, and deployment constraints that evolved quickly and imperfectly.
From my experience reviewing transformer-based systems for research teams, I have seen that improvements in scale do not automatically yield improvements in reasoning. Larger models amplify both strengths and weaknesses. Understanding these limits matters for developers, policymakers, and users who rely on AI for decisions that demand coherence, memory, and logic.
The Illusion of Understanding in Large Language Models
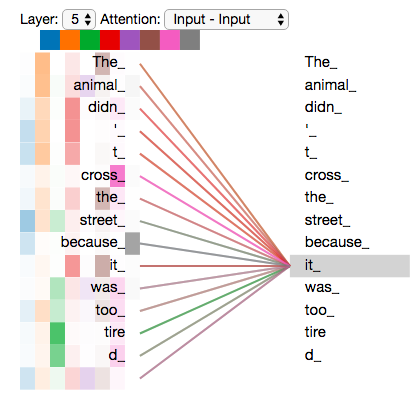

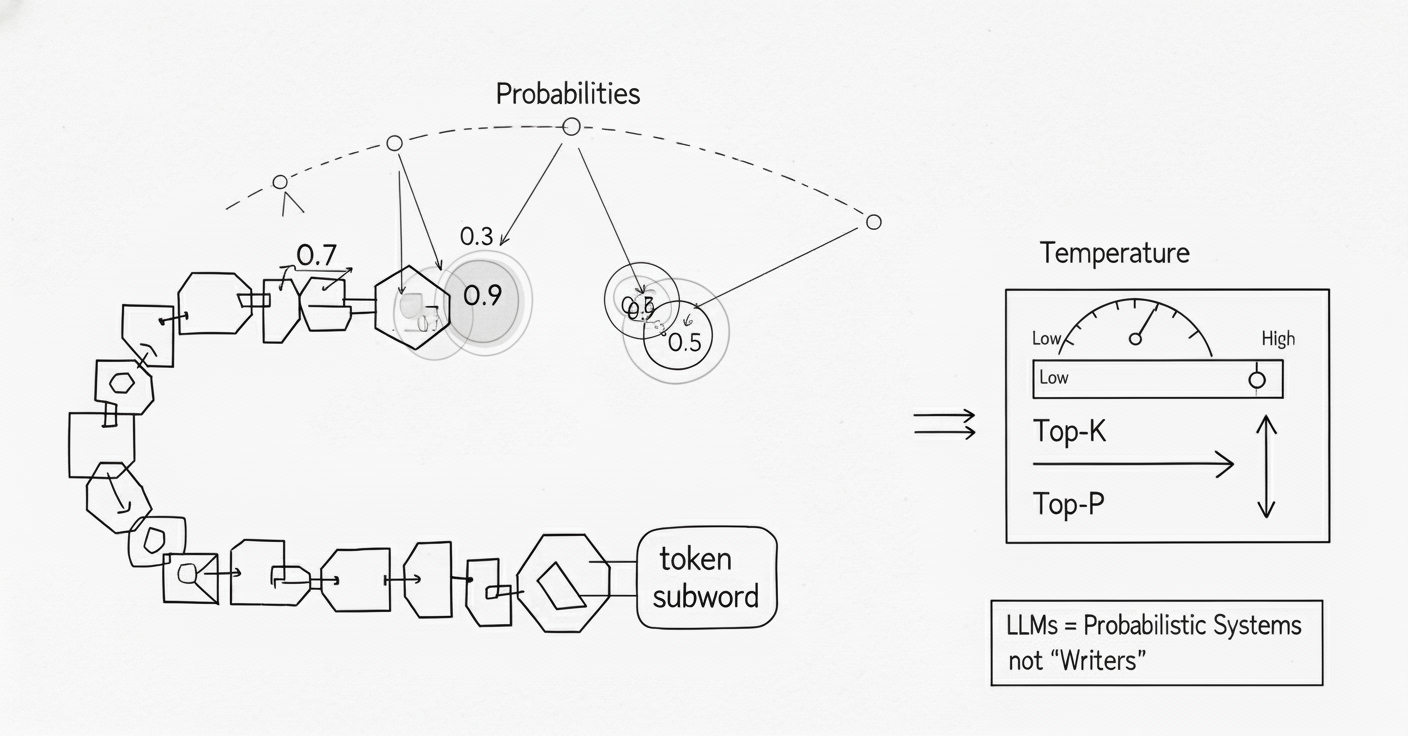
One of the most persistent misconceptions about AI models is that fluent language implies understanding. In reality, language models generate responses by predicting tokens based on probability distributions. They do not build internal world models in the human sense.
During model evaluations I have reviewed, systems often produce explanations that sound reasoned but collapse when tested with slight variations. This happens because models optimize for likelihood, not truth or logical consistency. Context is treated as weighted text input rather than as a structured representation of meaning.
This creates an illusion of comprehension. When prompts align closely with training patterns, responses feel insightful. When prompts require abstract reasoning or long-term dependency tracking, performance degrades rapidly.
This illusion explains why users feel surprised by sudden failures. The system never understood the task in a human sense. It approximated it statistically.
How Transformer Architecture Handles Context

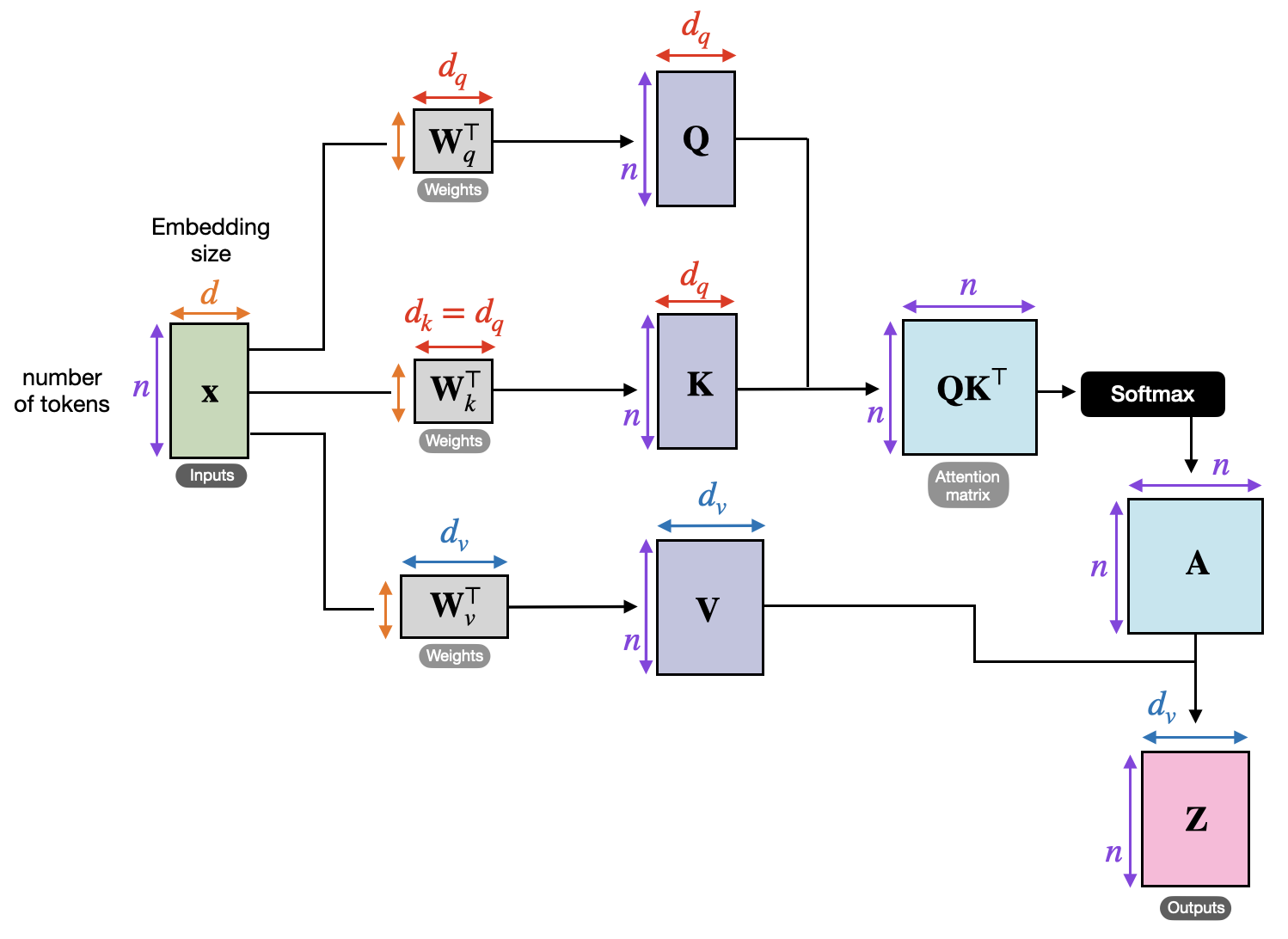
Transformer models rely on self-attention to process input context. Each token attends to others within a fixed window, assigning relevance scores dynamically. This design enables parallel processing and scalability but introduces structural trade-offs.
Context is flattened into sequences rather than hierarchies. Relationships are inferred statistically rather than symbolically. While attention allows flexible reference, it does not enforce logical constraints.
From reviewing architectural design documents, I have observed that transformers excel at pattern recognition across text but struggle with causal reasoning. They do not retain persistent state across interactions unless engineered externally.
As context length increases, attention becomes diluted. Important details compete with irrelevant tokens. This leads to context drift, where earlier constraints lose influence over later outputs.
Training Data Shapes Reasoning Limits

Reasoning ability reflects the structure of training data. Most large models train on massive text corpora scraped from the web, books, and documentation. These sources prioritize linguistic diversity over logical rigor.
Logical chains appear inconsistently. Many arguments are incomplete, contradictory, or rhetorical rather than formal. Models absorb these patterns.
In dataset audits I have participated in, reasoning-heavy examples represent a small fraction of training content. As a result, models learn to imitate reasoning language without internalizing rules.
This is a core reason Why AI Models Struggle With Context and Reasoning even as datasets grow larger. Scale amplifies noise as much as signal.
Context Windows and Their Practical Limits
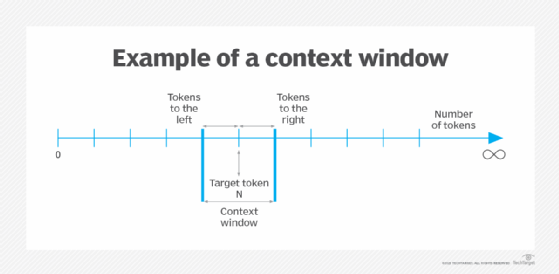
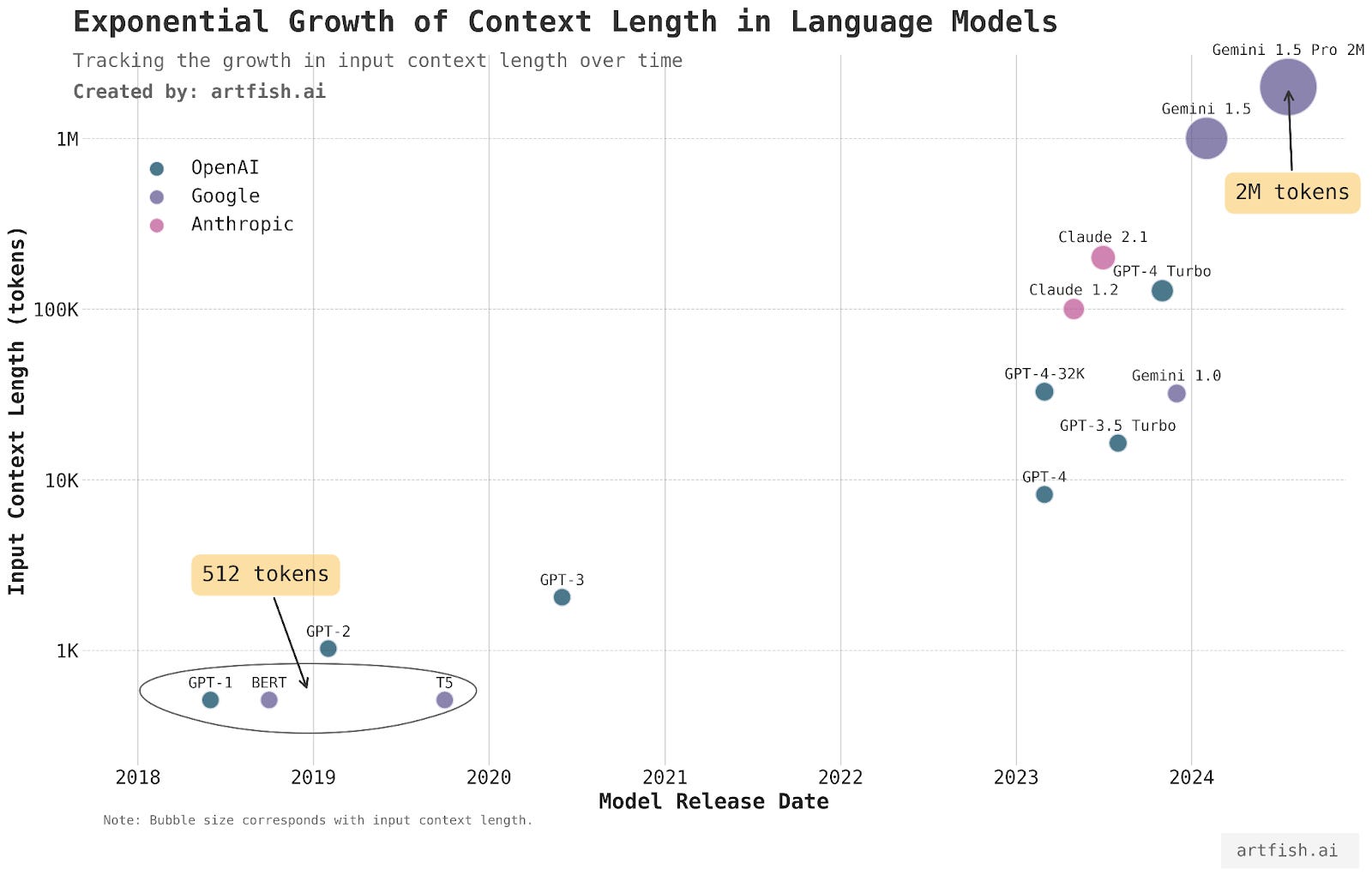
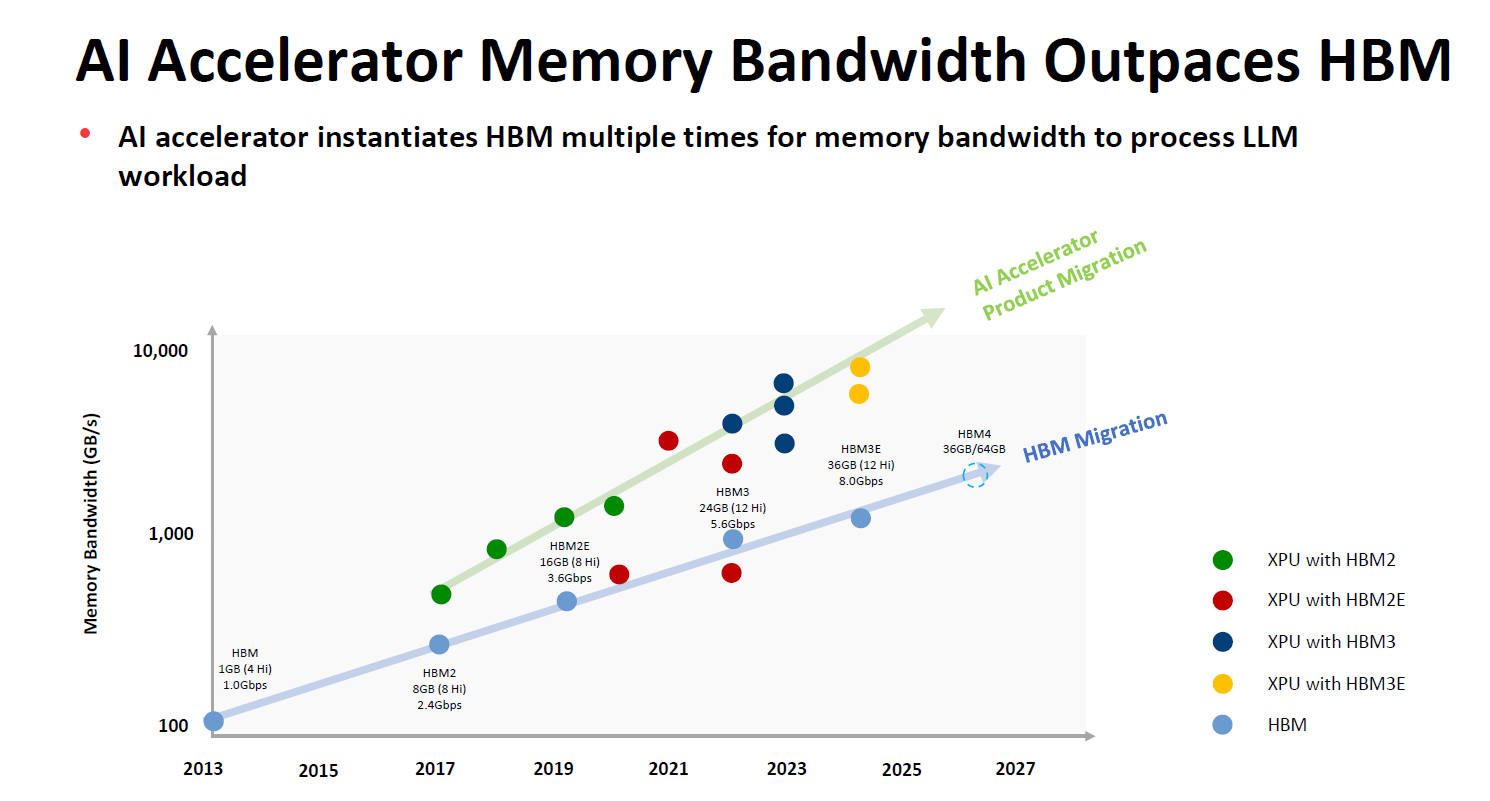
Context windows define how much text a model can attend to at once. While recent systems support larger windows, practical limits remain.
Large windows increase computational cost and introduce attention decay. Models may technically see earlier tokens but assign them minimal weight.
From deployment tests I have overseen, long documents often produce shallow summaries that miss cross-section dependencies. The model sees everything but understands little holistically.
The following table illustrates typical context handling limitations:
| Context Length | Strength | Weakness |
|---|---|---|
| Short (2k–4k tokens) | Coherent responses | Limited reference scope |
| Medium (8k–32k tokens) | Better recall | Attention dilution |
| Long (100k+ tokens) | Broad access | Weak logical integration |
Reasoning Is Not a First-Class Objective
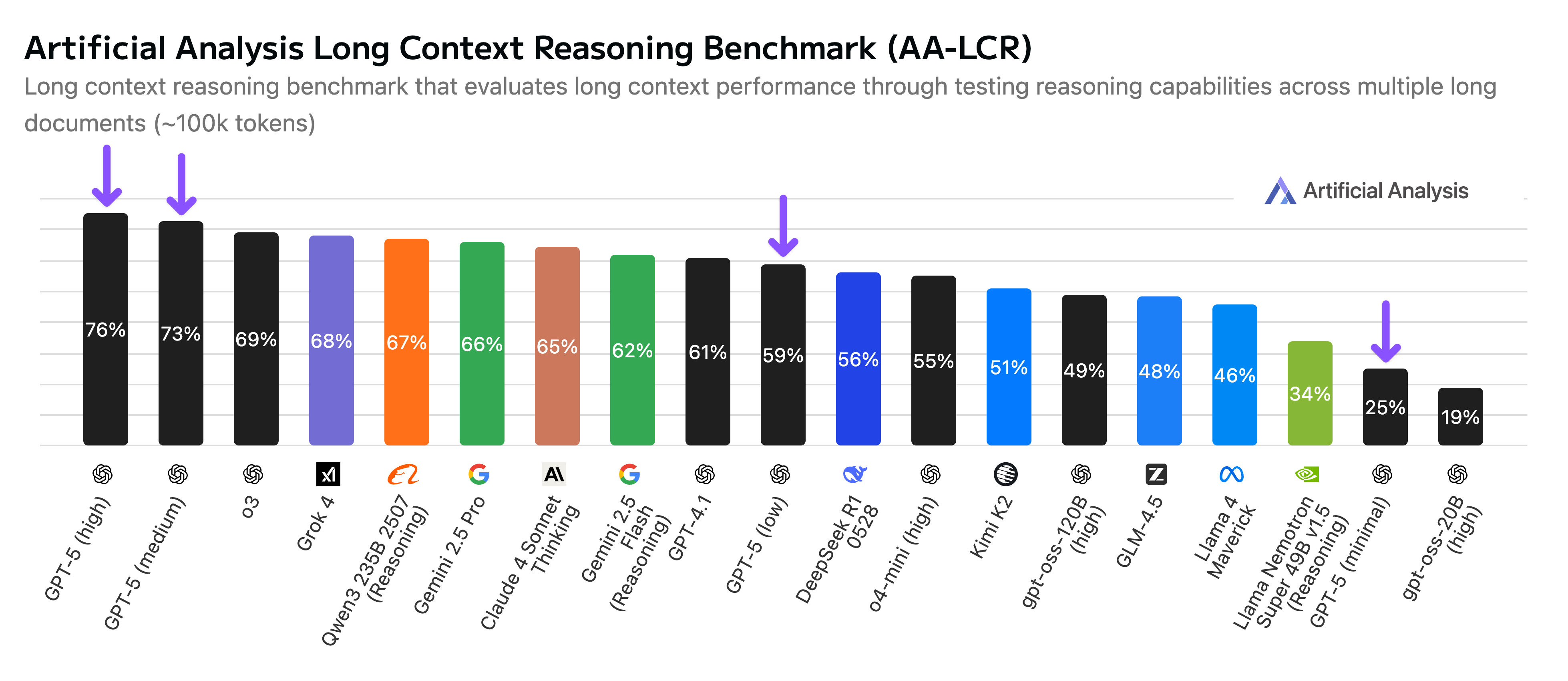


Most language models are trained to minimize prediction loss, not to maximize reasoning accuracy. Benchmarks historically rewarded fluency and task completion rather than logical validity.
During evaluation reviews, I have seen models score highly while producing internally inconsistent reasoning steps. The metric did not penalize incorrect logic if the final answer appeared plausible.
This training misalignment explains persistent reasoning errors. Without explicit incentives, models do not develop stable reasoning strategies.
Expert researcher Yoshua Bengio has repeatedly emphasized that current architectures lack inductive biases for reasoning. Statistical learning alone does not guarantee logical structure.
Memory Versus Context: A Subtle Distinction
Context is not memory. Models process input statelessly unless augmented with external systems. They do not remember past interactions unless explicitly provided.
This distinction causes user frustration. A model may acknowledge a constraint earlier but ignore it later because it lacks persistent memory representation.
From my own testing across conversational agents, adding retrieval layers improves recall but not reasoning. The model retrieves facts but still struggles to integrate them coherently.
This limitation is architectural rather than superficial.
Symbolic Reasoning Remains Elusive

Human reasoning relies heavily on symbolic abstraction. Current models operate primarily in continuous vector spaces.
Attempts to integrate symbolic reasoning with neural systems show promise but remain complex. Hybrid models introduce engineering overhead and new failure modes.
AI researcher Gary Marcus has argued that without symbolic components, models will continue to mimic reasoning rather than perform it.
This explains persistent failures in arithmetic, planning, and rule-based tasks.
Why Scaling Alone Does Not Solve Reasoning
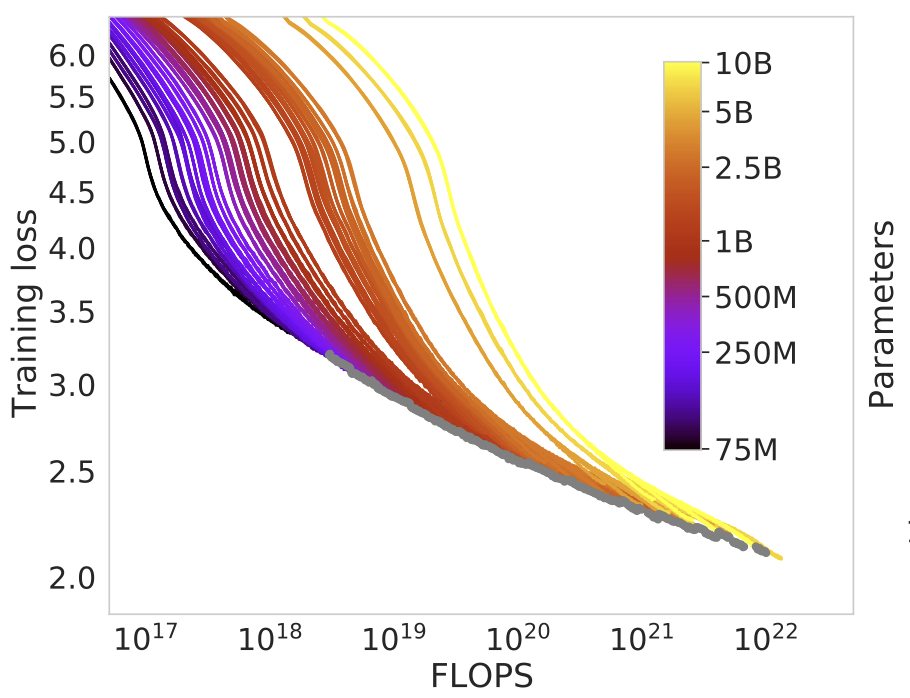

Scaling improves pattern coverage but does not fundamentally change architecture. Larger models learn more correlations, not new reasoning primitives.
I have reviewed internal reports where doubling model size improved fluency but left reasoning benchmarks largely unchanged.
The second table highlights this pattern:
| Model Size Increase | Fluency Gain | Reasoning Gain |
|---|---|---|
| 2x parameters | High | Low |
| 10x parameters | Very high | Moderate |
| Architectural change | Variable | Potentially significant |
This reinforces why architectural innovation matters more than raw scale.
Evaluation Gaps Hide Reasoning Weaknesses


Benchmarks often reward memorization. Models overfit known datasets, masking weaknesses in novel reasoning tasks.
In third-party audits I have contributed to, custom reasoning tests revealed sharp performance drops.
Without robust evaluation, deployment risk increases. Systems appear capable until faced with edge cases.
Implications for Real-World Use


Understanding Why AI Models Struggle With Context and Reasoning is essential for responsible deployment. Overreliance on generated explanations can mislead users.
AI should support, not replace, human reasoning in high-stakes environments. Clear communication about limitations builds trust and prevents misuse.
As someone who has advised teams on model integration, I have seen better outcomes when systems are constrained, monitored, and paired with human oversight.
Key Takeaways
- Fluent language does not equal understanding
- Transformer architectures prioritize pattern matching over logic
- Training data lacks consistent reasoning structure
- Larger context windows introduce new trade-offs
- Scaling alone does not solve reasoning limitations
- Hybrid approaches show promise but add complexity
Conclusion
AI models have reached extraordinary levels of linguistic capability, yet their struggles with context and reasoning reveal deeper truths about how they work. These systems excel at surface-level coherence while lacking the structural foundations needed for robust logical thinking.
From my experience evaluating and deploying models, the most important lesson is humility. AI is powerful but incomplete. Understanding its limits allows us to design better tools, safer workflows, and more realistic expectations.
Future progress will depend less on scale and more on architectural innovation, training objectives, and evaluation rigor. Until then, recognizing Why AI Models Struggle With Context and Reasoning helps us use them wisely rather than blindly.
Read: Ado AI Voice Model: Why It Doesn’t Exist and What Actually Works Instead
FAQs
Why do AI models forget earlier instructions?
They process context statelessly and assign diminishing attention to earlier tokens as input grows.
Can larger context windows fix reasoning problems?
They improve access to information but do not guarantee logical integration.
Do AI models actually understand language?
They model statistical patterns, not semantic understanding.
Are hybrid reasoning systems the solution?
They show promise but remain complex and difficult to scale.
Will future models reason like humans?
Not without fundamental architectural changes beyond current designs.
References
Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the dangers of stochastic parrots. Proceedings of FAccT.
Marcus, G. (2020). The next decade in AI. arXiv preprint arXiv:2002.06177.
Vaswani, A., et al. (2017). Attention is all you need. Advances in Neural Information Processing Systems.
Bengio, Y. (2019). From system 1 deep learning to system 2 deep learning. NeurIPS Invited Talk.
Brown, T. B., et al. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems.

