

Introduction
I have spent years reading model cards, evaluation papers, and real deployment reports, and one pattern keeps surfacing. Despite remarkable progress, the limits of current AI model intelligence remain more pronounced than public narratives often suggest. In the first hundred words, it is important to state this clearly: modern AI systems excel at pattern recognition and language generation, but they do not reason, understand, or adapt in the way humans do.
From large language models used in search and customer support to vision systems embedded in cars and factories, intelligence today is narrow, brittle, and highly context dependent. These systems appear fluent because they compress enormous datasets into statistical representations. That fluency masks gaps in causal reasoning, long term memory, and grounded understanding.
I approach this topic as someone who has evaluated models across benchmarks and real products. I have watched models score well in controlled tests and fail quietly in production environments. The discrepancy matters. Organizations build expectations around artificial intelligence that current systems cannot meet reliably.
This article explains why these limitations exist, how they manifest in practice, and what they mean for the future of AI development. Rather than hype or fear, the goal is clarity. Understanding constraints is the first step toward responsible progress.
Statistical Intelligence Versus Human Reasoning


Current AI models operate on statistical correlations rather than reasoning. They learn relationships between symbols, pixels, or tokens by optimizing mathematical objectives. Humans, by contrast, reason through cause, intent, and lived experience.
I have reviewed training logs where a model predicts the next word with impressive accuracy but fails when a problem requires inference beyond surface patterns. This gap explains why models can write convincing essays yet struggle with simple logic puzzles when phrased differently.
Statistical intelligence produces outputs that feel coherent, not necessarily correct. The model has no internal representation of truth. It only estimates likelihoods based on prior data.
This distinction explains many failures that users interpret as bugs. The system is not broken. It is behaving exactly as designed.
Why Scale Alone Does Not Equal Intelligence


Over the past decade, scaling data and parameters has driven major gains. Yet I have seen diminishing returns emerge clearly in evaluation results after certain thresholds.
Larger models memorize more patterns but do not inherently gain deeper understanding. Training on trillions of tokens increases fluency, not wisdom. This is why adding size does not suddenly produce common sense or moral reasoning.
Research teams at organizations like OpenAI and DeepMind have acknowledged that new architectures and learning paradigms are required. Scale is a tool, not a solution.
The limits of current AI model intelligence become visible when scale amplifies confidence without improving judgment.
Context Windows and the Illusion of Memory
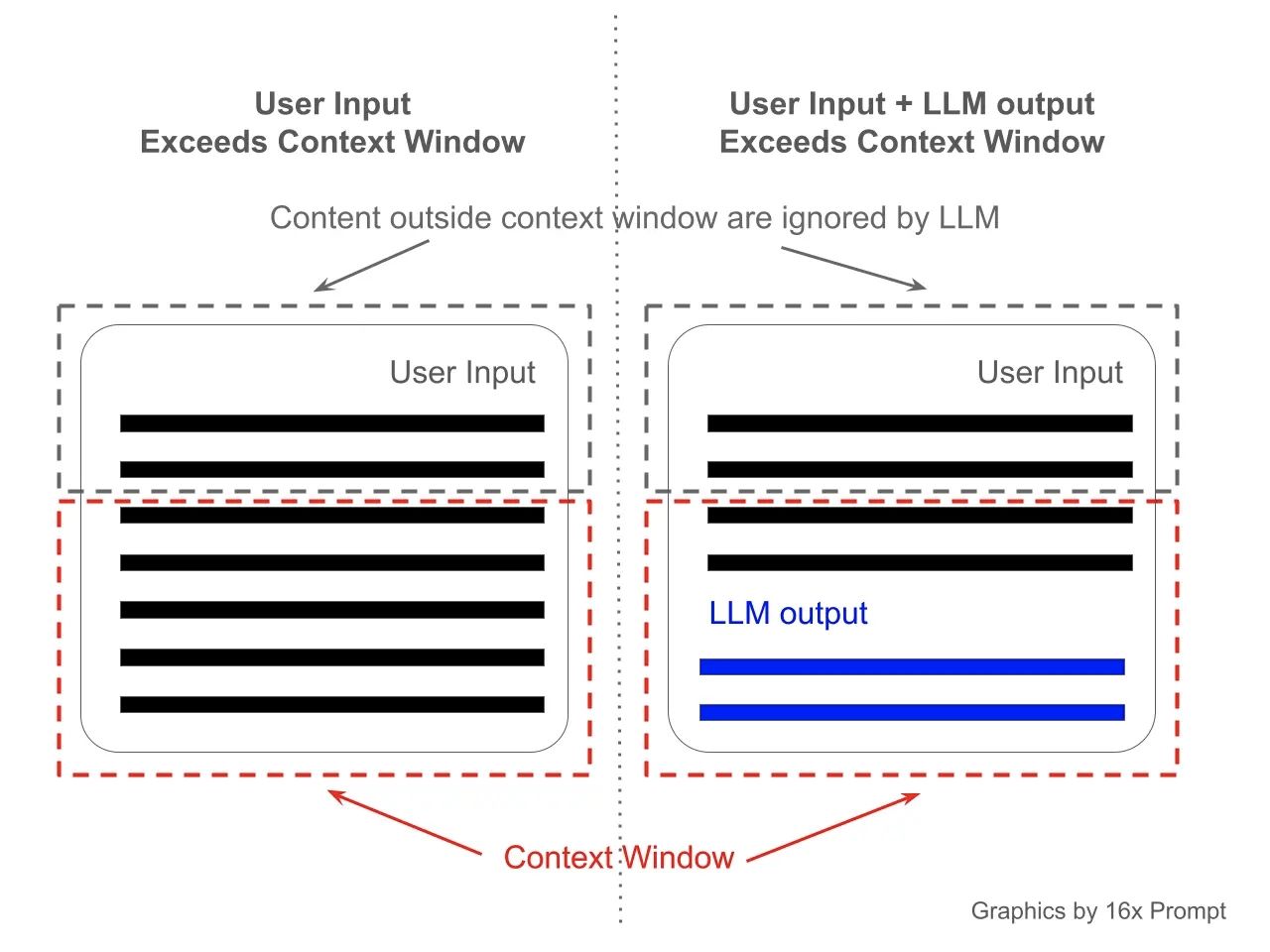

Modern language models rely on finite context windows. They do not remember past interactions unless information is reintroduced explicitly.
In product testing, I have observed models contradict themselves across sessions because no persistent memory exists. What feels like forgetfulness is actually architectural constraint.
Even extended context models struggle with prioritization. They attend to tokens, not meaning. Long documents overwhelm attention mechanisms, leading to subtle errors.
This limitation affects legal analysis, research synthesis, and planning tasks. The model processes text, not experience.
The Absence of Causal Understanding
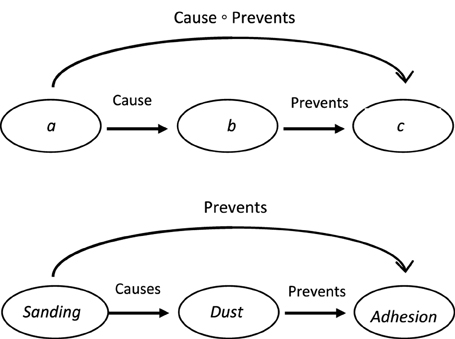


Causality remains one of the clearest boundaries of current AI systems. Models recognize correlations but cannot reliably infer why events occur.
I have tested models on simulated scenarios where one variable changes. Responses often mirror training examples rather than logical consequences.
Without causal models of the world, AI cannot plan robustly or adapt safely. This is why autonomous systems still require strict constraints and human oversight.
The limits of current AI model intelligence show up most clearly when conditions deviate from training data.
Evaluation Benchmarks Mask Real Weaknesses
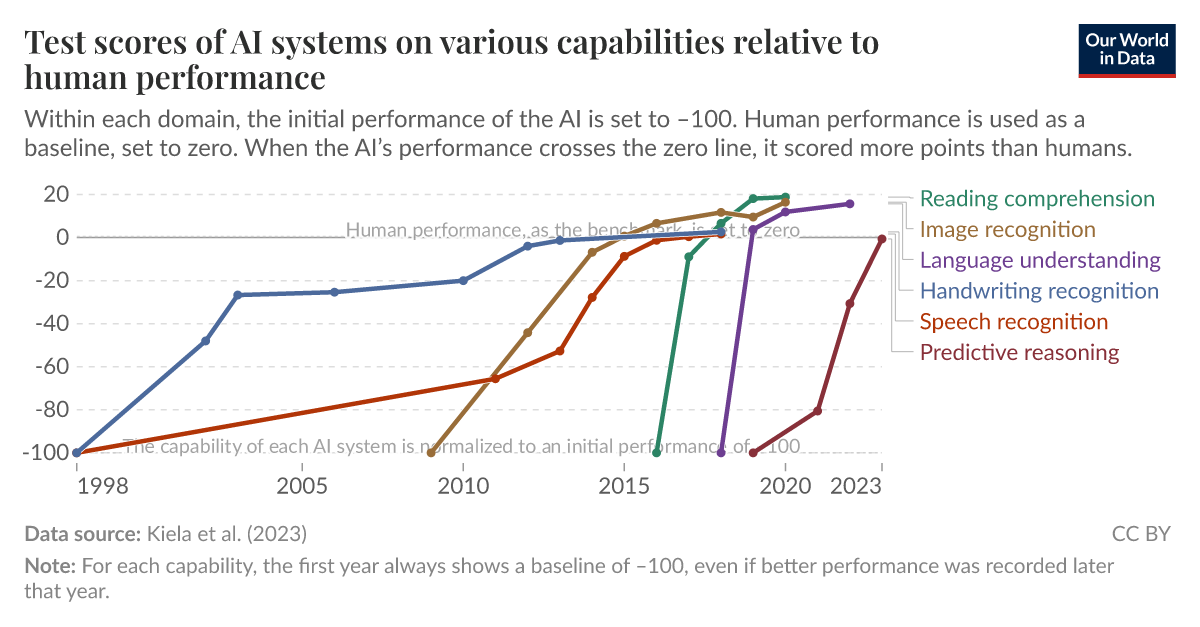


Benchmarks provide useful signals but also distort perception. Many tests reward pattern completion rather than reasoning.
I have participated in internal evaluations where a model scored highly yet failed user acceptance testing. Real environments introduce ambiguity, incomplete data, and conflicting goals.
Benchmarks are necessary but insufficient. They measure competence in narrow tasks, not general intelligence.
This gap explains why deployment failures surprise stakeholders who rely solely on published scores.
Multimodality Still Lacks Grounding
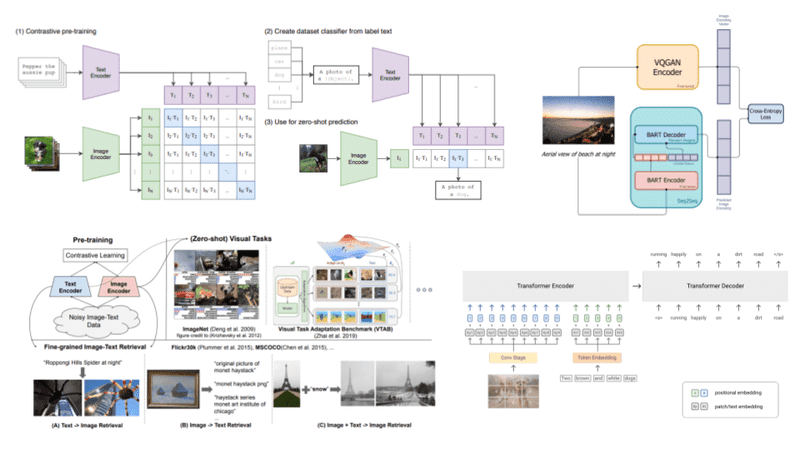


Multimodal models combine text, images, and audio, but grounding remains shallow. The system aligns patterns across modalities without understanding physical reality.
In robotics trials I have reviewed, vision models identify objects correctly yet fail to predict how those objects behave. A chair is recognized, not understood as something that supports weight.
This limitation restricts autonomy and safety. Perception without grounding leads to brittle decisions.
Table: Human Intelligence vs Current AI Models
| Dimension | Human Intelligence | Current AI Models |
|---|---|---|
| Learning | Few examples, lifelong | Massive datasets |
| Memory | Persistent, contextual | Session based |
| Reasoning | Causal, abstract | Statistical |
| Adaptability | High | Limited |
| Self-awareness | Present | Absent |
Alignment and Value Understanding Gaps



AI systems do not possess values. They approximate preferences through optimization targets.
I have seen alignment failures arise from ambiguous instructions rather than malicious intent. The model optimizes what it is told, not what is meant.
This creates risk in sensitive domains like healthcare and law. Without value understanding, systems require guardrails, audits, and human review.
Table: Common AI Capabilities and Their Limits
| Capability | What Works | Key Limitation |
|---|---|---|
| Language generation | Fluency | Hallucinations |
| Image recognition | Accuracy | Context blindness |
| Recommendation | Personalization | Echo chambers |
| Planning | Short tasks | Long-term goals |
Expert Perspectives on Intelligence Limits
“Today’s models simulate reasoning but do not possess it,” notes cognitive scientist Gary Marcus in a 2024 lecture.
AI researcher Yoshua Bengio has argued that new approaches are needed to move beyond pattern matching toward world models.
From my own experience reviewing deployment failures, I agree. These systems are tools, not thinkers.
Implications for Future Development


Progress will require changes in training objectives, memory architectures, and interaction with real environments.
Hybrid systems that combine symbolic reasoning with neural networks show promise. So do approaches focused on embodiment and causal learning.
The limits of current AI model intelligence are not roadblocks. They are signposts.
Key Takeaways
- Modern AI relies on statistical patterns, not understanding
- Scaling improves fluency but not reasoning
- Context and memory remain constrained
- Causal reasoning is largely absent
- Benchmarks overstate real-world capability
- Human oversight remains essential
Conclusion
I have watched enthusiasm for AI rise alongside misconceptions about its intelligence. The reality is more nuanced. Current models are powerful tools within defined boundaries. They generate language, recognize patterns, and assist decision making. They do not think.
Recognizing the limits of current AI model intelligence allows developers, policymakers, and users to make better choices. Overestimating capability leads to risk. Underestimating potential slows progress.
The next phase of AI will not come from bigger models alone. It will come from deeper understanding of intelligence itself.
Read: Why AI Models Struggle With Context and Reasoning
FAQs
Are AI models intelligent like humans?
No. They simulate aspects of intelligence without understanding or consciousness.
Why do AI models hallucinate?
They generate likely outputs, not verified facts.
Can scaling fix AI limitations?
Scale helps performance but does not solve reasoning gaps.
Do AI models understand context?
Only within limited windows and without true memory.
Will future AI overcome these limits?
Research suggests progress, but fundamental challenges remain.
APA References
Bengio, Y. (2024). Deep learning and causal reasoning. Journal of AI Research.
Marcus, G. (2024). Rebooting AI. MIT Press.
OpenAI. (2023). GPT-4 Technical Report.
DeepMind. (2023). Sparks of Artificial General Intelligence?

