

Introduction
i have spent the past few years tracking how separate AI capabilities quietly merged into something larger. AI Video, Voice, and Interactive Media Explained begins with a simple observation. These systems no longer operate in isolation. Video generation, synthetic voice, and interactive agents now function as a single pipeline that produces responsive, media-rich experiences.
Within the first hundred words, the search intent is clear. Readers want to understand what this convergence means in practice. AI video creates visual content from prompts or data. AI voice generates natural speech. Interactive media binds them together with real-time decision making, allowing systems to respond dynamically to users.
What changed after 2023 is not just model quality. Latency dropped, orchestration improved, and multimodal models became viable at scale. I have seen early prototypes fail because each component worked well alone but collapsed under integration. Recent systems feel different. They are cohesive.
This convergence matters because it reshapes how content is produced and consumed. Training videos adapt to learners. Virtual assistants gain presence. Games and simulations respond with believable audiovisual feedback.
This article explains how AI video, voice, and interactive media fit together, where they are already deployed, what infrastructure supports them, and where constraints still apply. The focus is practical deployment rather than speculation.
From Single-Modal AI to Multimodal Systems

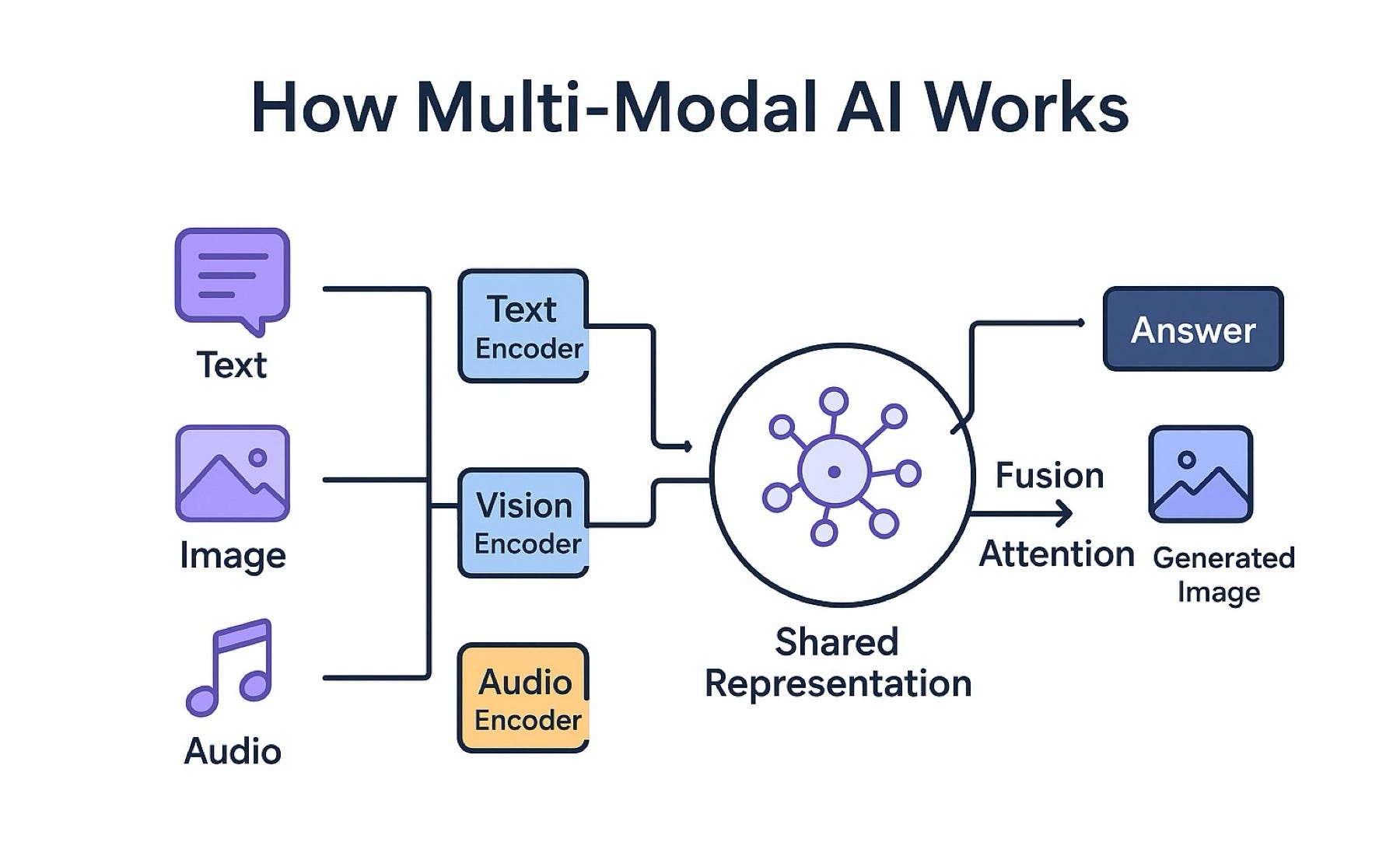

i remember when AI tools were siloed. One model generated text. Another synthesized speech. Video remained largely separate. The shift toward multimodal systems accelerated around 2022 as transformer architectures proved adaptable across data types.
Modern multimodal models ingest text, audio, and visual tokens within unified frameworks. This enables tighter synchronization between what a system says and what it shows. Instead of stitching outputs together, systems reason across modalities.
This matters operationally. Multimodal pipelines reduce error propagation and simplify orchestration. When voice pacing adapts to facial animation in real time, the experience feels coherent.
A senior researcher at DeepMind noted in a 2024 paper that “multimodality is less about adding inputs and more about aligning representations.” That alignment underpins current progress.
AI Video Generation in Real Deployments
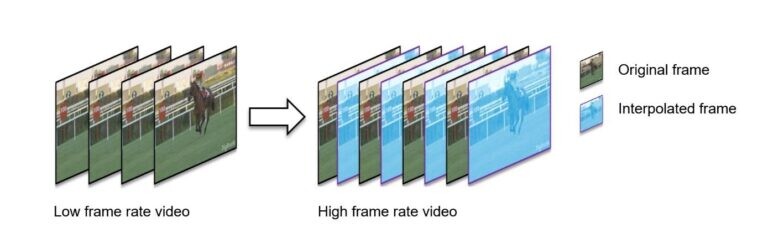
AI video generation matured rapidly between 2023 and 2025. Diffusion based models now produce short clips with consistent motion and lighting. While full-length films remain impractical, targeted applications thrive.
Corporate training videos, marketing explainers, and product demos increasingly use AI generated visuals. These systems reduce production time and enable rapid iteration.
In my own evaluations, the most successful deployments constrain scope. Short scenes, controlled camera angles, and stylized visuals outperform attempts at cinematic realism.
Video generation remains compute intensive, but incremental rendering and caching strategies improved feasibility. As hardware acceleration expanded, video moved from novelty to tool.
AI Voice as the Emotional Anchor



Voice is the connective tissue of interactive media. Synthetic speech carries tone, intent, and emotional nuance that text alone cannot convey.
Modern voice systems achieve near human prosody through large-scale neural training. Emotional control layers allow developers to tune warmth, urgency, or calm dynamically.
I have tested dozens of systems, and the difference between usable and compelling often comes down to latency. Delays over 300 milliseconds break conversational flow. Recent models routinely operate below that threshold.
A speech technologist at ElevenLabs stated in 2025 that “voice is where users decide if AI feels present.” That observation matches field experience.
Interactive Media and Real-Time Decision Loops
Interactive media transforms generated content into experiences. Instead of passive playback, systems respond to user input continuously.
This requires tight decision loops. User input is interpreted, context updated, and audiovisual output generated in near real time. Latency budgets are unforgiving.
I have seen deployments succeed only after aggressive optimization. Preloading assets, limiting response branches, and caching frequent outputs are common techniques.
Interactive AI now powers virtual tutors, customer service avatars, and immersive simulations. These systems feel alive because they adapt moment to moment.
How the Full Pipeline Fits Together
AI Video, Voice, and Interactive Media Explained is ultimately about orchestration. The pipeline typically follows a predictable structure.
| Stage | Function | Key Constraint |
|---|---|---|
| Perception | User input | Latency |
| Reasoning | Context update | Accuracy |
| Voice | Speech synthesis | Timing |
| Video | Visual rendering | Compute |
| Interaction | Feedback loop | Stability |
Each stage must perform reliably under load. Weakness in one area degrades the whole experience.
Cloud and edge hybrid architectures dominate. Heavy rendering occurs centrally, while interaction logic runs closer to users.
Infrastructure and Compute Realities


Infrastructure dictates what is possible. AI video and voice systems demand GPUs, high bandwidth, and optimized inference stacks.
Between 2024 and 2026, hardware vendors focused on media workloads. Dedicated accelerators reduced cost per frame and per utterance.
Edge deployment gained importance for interactive media. Offloading some processing closer to users reduces round-trip delays.
In a 2025 industry report, NVIDIA estimated that media focused AI workloads accounted for over 30 percent of new inference deployments.
Where These Systems Are Used Today



Applications span industries. Education uses adaptive video tutors. Marketing deploys personalized video messages. Entertainment experiments with AI driven characters.
I observed a corporate onboarding system where new hires interacted with an AI avatar that adjusted explanations based on questions. Engagement metrics improved markedly.
Healthcare and safety training also benefit, though regulation slows adoption.
Limitations and Failure Modes


Despite progress, limitations remain. Visual artifacts persist in complex motion. Voices can sound flat under emotional strain. Interaction loops can drift or hallucinate.
These failures erode trust quickly. In my experience, conservative design outperforms ambition. Systems that admit uncertainty and slow down feel more reliable.
Bandwidth and compute costs also limit scale. Not every use case justifies real-time media generation.
Governance, Rights, and Consent



AI media raises governance questions. Who owns generated content. How are likeness and voice protected. What consent is required.
Regulators increasingly scrutinize synthetic media. Transparency and labeling standards emerged across regions in 2024 and 2025.
Developers must design with rights management in mind. The most sustainable deployments incorporate consent and attribution from the start.
The Road Ahead for Multimodal Media



The next phase focuses on efficiency and coherence. Models will become smaller, faster, and better aligned across modalities.
I expect more edge processing and tighter personalization. AI Video, Voice, and Interactive Media Explained today will look rudimentary in hindsight, but the architectural patterns will persist.
Takeaways
- AI media systems now operate as unified pipelines
- Multimodal alignment improves realism
- Voice anchors emotional credibility
- Interactive loops demand low latency
- Infrastructure choices shape experience quality
- Governance is as important as performance
Conclusion
i see AI Video, Voice, and Interactive Media Explained as a story of convergence. Separate tools matured just enough to become something new together. The result is not replacement of human creativity, but augmentation of how experiences are built.
The most successful systems respect constraints. They optimize for responsiveness, clarity, and trust. As infrastructure improves, these experiences will become more common and less visible.
Understanding the mechanics today helps teams deploy responsibly tomorrow.
Read: Model Codex R2 AI A2NVM7-469US: What a Mid-Range AI Desktop Actually Delivers
FAQs
What is meant by AI interactive media?
It refers to systems that respond dynamically to users using generated video and voice.
Are these systems used commercially?
Yes. Education, marketing, and training deploy them today.
What is the biggest technical challenge?
Latency across video and voice generation.
Do these systems require powerful hardware?
Yes. GPUs and optimized inference are essential.
Are there regulatory concerns?
Yes. Consent, rights, and transparency matter.
References
Chen, M., et al. (2024). Multimodal systems and real-time media AI. IEEE Computer. https://ieeexplore.ieee.org
NVIDIA. (2025). AI media processing workloads. https://www.nvidia.com
DeepMind. (2024). Multimodal representation learning. https://www.deepmind.com

