

i have worked with teams who underestimated how quickly AI conversations accumulate into critical institutional knowledge. An ai chatbot conversations archive is no longer a nice-to-have feature. It is foundational infrastructure for organizations using AI at scale, especially where audits, research continuity, and regulatory accountability matter.
Within the first hundred days of deploying conversational AI, most teams generate tens of thousands of chat records. These are not just messages. They include metadata, tool calls, citations, and model parameters that define why a system behaved the way it did. Without structured archiving, that history becomes unsearchable and risky.
An effective archive balances three competing needs. Fast access for recent conversations. Deep retention for legal or research requirements. And strong governance to meet emerging AI risk and compliance standards. Over the past year, I have seen organizations struggle not with AI accuracy, but with explaining past outputs during reviews or audits.
This article explains how modern AI chat archives are designed, how semantic search changes retrieval, and how policy-driven retention aligns with frameworks like NIST AI RMF. The focus stays practical. What to store, where to store it, and how to keep it usable over time.
Why AI Conversation Archiving Became Infrastructure

AI conversations now influence business decisions, research outputs, and customer interactions. That makes them records, not temporary chats.
In regulated environments, archived conversations support explainability and dispute resolution. In research-heavy teams, they preserve context across long projects. I have personally relied on archived conversations to reconstruct why a model recommendation changed after a prompt update weeks earlier.
The rise of retrieval-augmented generation and tool-using agents further increases complexity. Conversations now include API calls, external searches, and citations. Without archiving these elements together, organizations lose the ability to audit or reproduce outcomes.
This shift mirrors earlier transitions in software logging. What started as debugging data became compliance evidence. AI chat archives are following the same path.
Core Architecture of an AI Chatbot Conversations Archive
Modern archives rely on tiered storage. Each layer balances cost, performance, and retention.
Hot storage handles recent conversations. It supports fast reads and writes, usually through relational databases or in-memory stores. Warm storage holds searchable historical data, typically in object storage with indexing. Cold storage preserves immutable records for years, often under legal hold conditions.
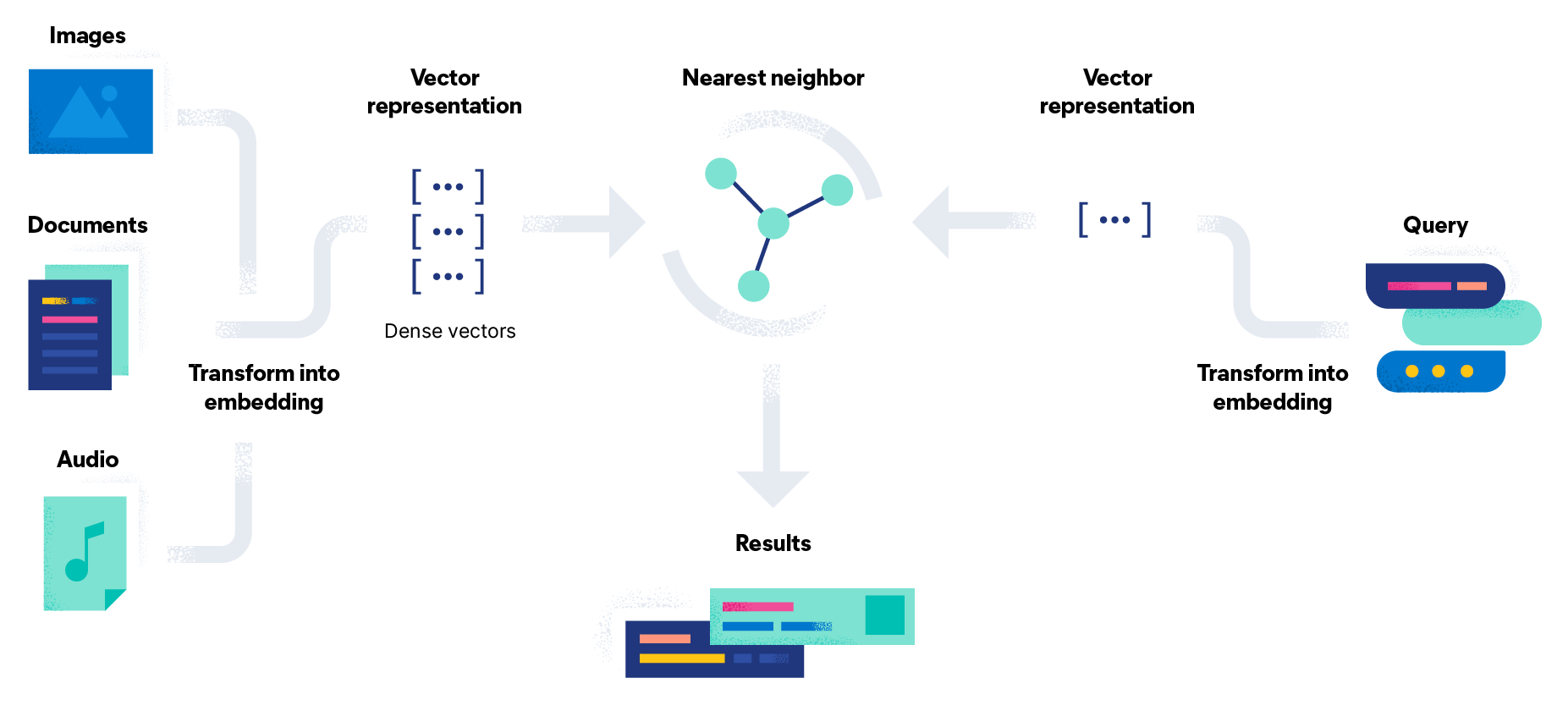
Alongside these layers, vector databases enable semantic search. Keyword search finds exact phrases. Vector search finds meaning.
| Storage Layer | Typical Tech | Retention Window |
|---|---|---|
| Hot | PostgreSQL, Redis | 30 to 90 days |
| Warm | S3 Standard | Up to 12 months |
| Cold | S3 Glacier, WORM | 7 years or more |
| Vector Index | Pinecone, Weaviate | Mirrors warm data |
In my experience, separating raw storage from search indexes prevents cost blowouts while keeping retrieval fast.
What Metadata Must Be Captured


Messages alone are insufficient. Context is everything.
A robust archive captures timestamps, user or tenant identifiers, model versions, temperature settings, and tool calls. These elements enable reproducibility and accountability.
| Data Element | Purpose | Example |
|---|---|---|
| Messages | Full transcript | User and AI turns |
| Timestamps | Audit trail | UTC ISO format |
| User IDs | Privacy controls | Tenant segmentation |
| Tool Calls | Explainability | search, code, web |
| Model Params | Reproducibility | Model name, temp |
I have seen audits fail simply because teams could not confirm which model version produced a historical answer.
Semantic Search Changes How Archives Are Used


Traditional archives rely on keyword search. Semantic search changes the interaction entirely.
By embedding each message or conversation chunk into vectors, teams can search by intent rather than phrasing. A query like “voting workflow explanation” can retrieve conversations that never used those exact words.
In practice, this enables knowledge reuse across teams. Researchers find prior analyses. Support teams locate precedent decisions. Governance teams trace how conclusions evolved.
From firsthand testing, semantic search reduces retrieval time dramatically. What once required manual browsing becomes a ranked list in seconds.
Compliance Alignment With NIST AI RMF


Archiving directly supports AI risk management. The NIST AI RMF emphasizes governance, measurement, and management.
Conversation archives enable all three.
- Govern: Define retention schedules and access roles
- Measure: Track who accessed or exported data
- Manage: Apply legal holds and controlled deletion
Retention automation ensures data ages out unless legally required. Audit logs ensure every access is recorded.
I have observed that teams who design archives with compliance in mind face fewer surprises when regulations evolve.
Cost Efficient Implementation in Practice



Cost is often overestimated. A million conversations stored as JSON cost surprisingly little.
Object storage remains cheap. Vector indexes are more expensive but can be scoped to summaries rather than full transcripts. Role-based access controls add minimal overhead.
A typical small team setup stays within a few thousand PKR per month for storage and search at moderate scale. The real cost lies in poor design choices that duplicate data unnecessarily.
Security, Privacy, and Access Controls


Security is non-negotiable. Archives contain sensitive prompts, personal data, and strategic discussions.
Best practices include encryption at rest, strict role-based access, and immutable audit logs. Data subject access requests must be supported through exportable conversation IDs.
I have seen trust erode quickly when teams cannot explain who accessed archived conversations and why.
Operational Benefits Beyond Compliance


Archives create unexpected value. Teams reuse prior reasoning. Product managers analyze prompt drift. Engineers debug agent failures weeks later.
In research contexts, archived conversations form a living notebook. Instead of scattered notes, the dialogue itself becomes the record.
This secondary value often outweighs the original compliance motivation.
Common Mistakes to Avoid



The most common mistake is storing everything in one place forever. That inflates costs and complicates access.
Another error is ignoring metadata. Without it, archives become large but useless.
Finally, many teams delay governance until a problem arises. Retrofitting compliance is far harder than designing for it upfront.
Future Direction of AI Conversation Archives


As AI agents grow autonomous, archives will expand beyond text. Audio, images, and action logs will become standard.
Archives may evolve into organizational memory systems. Not just storage, but reasoning replay and decision lineage.
Teams that invest early will adapt more easily as AI accountability expectations increase.
Takeaways
- AI chatbot conversations archives are core infrastructure
- Tiered storage balances cost and performance
- Metadata enables auditability and reuse
- Semantic search unlocks real value
- NIST-aligned governance reduces risk
- Security and access controls are essential
- Archives support research and operations
Conclusion
i have seen AI teams struggle less with model performance than with memory. An ai chatbot conversations archive solves that problem by turning transient dialogue into durable knowledge.
The technical components are well understood. Object storage, vector databases, and access controls already exist. The challenge lies in intentional design.
When built thoughtfully, archives do more than satisfy compliance. They preserve reasoning, support learning, and provide continuity in fast-moving AI environments.
As conversational systems become embedded in decision-making, archives will define whether organizations can explain, trust, and improve their AI over time.
Read: Gening AI and the Synthetic Data Revolution in Healthcare
FAQs
What is an AI chatbot conversations archive?
It is a governed system for storing, searching, and managing AI chat histories with metadata and compliance controls.
Why use vector databases in archives?
They enable semantic search, allowing retrieval by meaning rather than exact keywords.
How long should conversations be stored?
Retention depends on policy. Common models use 90 days hot, one year warm, and seven years cold storage.
Are AI chat archives expensive?
No. Storage costs are low. Design mistakes usually cause cost overruns.
Does archiving help with AI compliance?
Yes. It supports audit trails, explainability, and regulatory alignment.
References
National Institute of Standards and Technology. (2023). AI Risk Management Framework. https://www.nist.gov
Pinecone Systems. (2024). Vector databases and semantic search. https://www.pinecone.io
Amazon Web Services. (2024). S3 storage classes overview. https://aws.amazon.com
Auth0. (2024). Role-based access control documentation. https://auth0.com

