

I have reviewed many applied AI systems that promise insight into human traits, but few provoke as immediate a reaction as the AI attractiveness test. Within seconds of uploading a photo, users receive a numerical beauty score and a breakdown of facial features. These tools claim to quantify attractiveness using facial symmetry, proportions, and alignment with mathematically defined ratios. For many people, curiosity drives the first interaction. For researchers, designers, and platform builders, the technology raises deeper questions about bias, validity, and societal consequences.
An AI attractiveness test is a computer vision application that evaluates static facial images using trained models. These systems analyze geometry, texture, and feature relationships, then output a score, usually on a scale of one to ten. Popular free tools such as Photoeval, HowAttractiveAmI, and Fotor make the process accessible without registration. The ease of use explains their viral appeal.
What interests me is not whether these scores define beauty. They do not. What matters is how algorithmic evaluation shapes perception, self image, and decision making. In this article, I examine how these systems work, what research says about their reliability, and where their limits begin.
How AI Learns to Measure Faces



AI attractiveness tests rely on computer vision models trained to detect facial landmarks. These landmarks include eye spacing, jawline contours, nose length, and facial symmetry. The system converts visual information into numerical features and compares them against learned patterns associated with higher ratings.
I have examined similar pipelines in biometric systems. The key insight is that these models do not understand beauty. They learn correlations between geometric consistency and human-labeled attractiveness datasets. When people consistently rate certain facial proportions higher, the model internalizes those patterns.
The golden ratio often appears in explanations, but in practice, modern models use multivariate feature relationships rather than a single mathematical constant. This distinction matters because it explains why scores can vary across platforms even for the same image.
The Scoring Process Explained
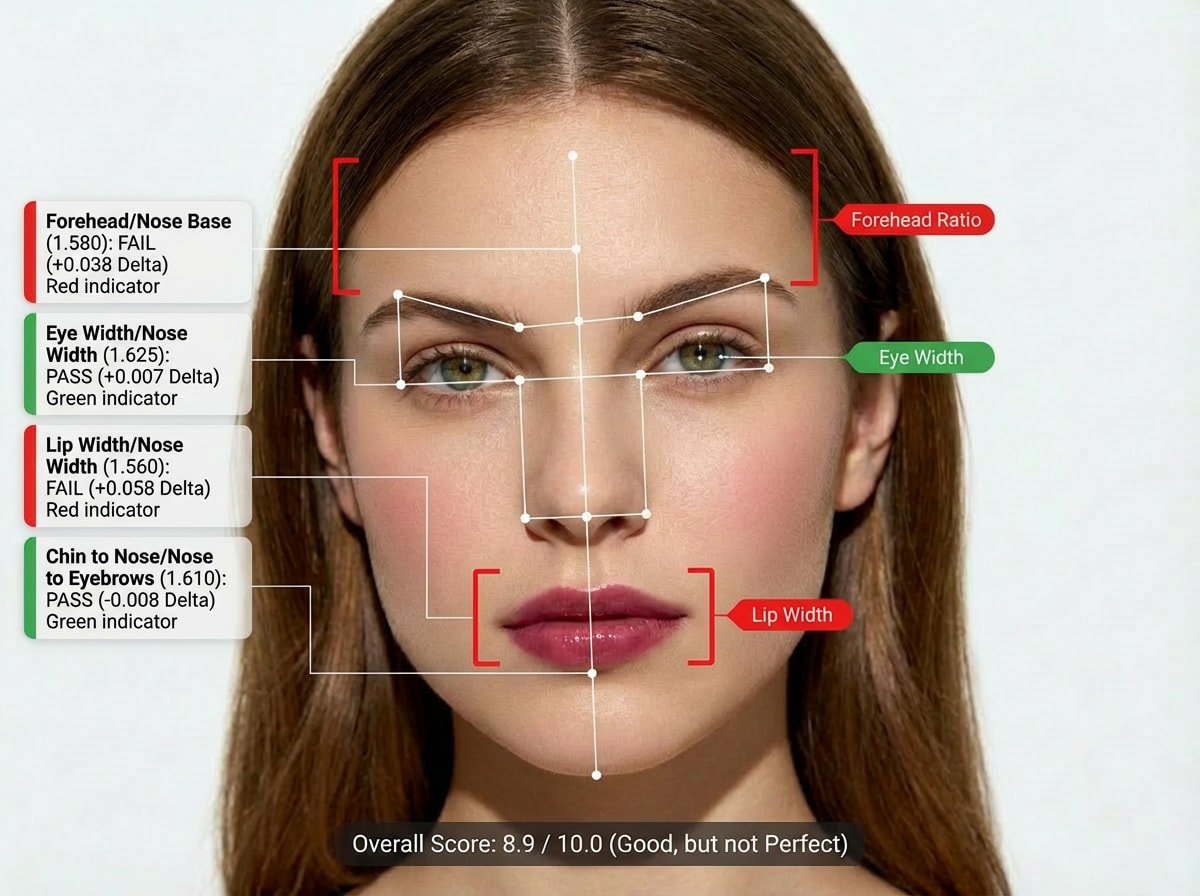

The workflow behind an AI attractiveness test is straightforward but precise. Users upload a clear, front-facing image with neutral lighting. The system detects the face, aligns it, and normalizes scale. Feature extraction follows, generating hundreds of measurements.
These measurements feed into a predictive model that outputs a score and feature insights. Some tools extend the output with styling or grooming suggestions. The entire process typically completes within ten seconds.
What I find notable is consistency. When the same photo is uploaded repeatedly, scores rarely change. This temporal stability contributes to user trust, even if the underlying concept remains subjective.
Popular Free AI Attractiveness Tools Compared
| Tool | Score Format | Key Focus | Privacy Approach |
|---|---|---|---|
| Photoeval | 1 to 10 | Symmetry and texture | Anonymous |
| HowAttractiveAmI | 1 to 10 | Golden ratio features | No signup |
| Fotor AI | Percentage | Face shape and skin | Instant results |
| Media.io | Multi trait | Beauty plus confidence | Downloadable card |
The table shows how tools differentiate through presentation rather than core technology. All rely on similar visual analysis pipelines.
Scientific Evidence and Validation
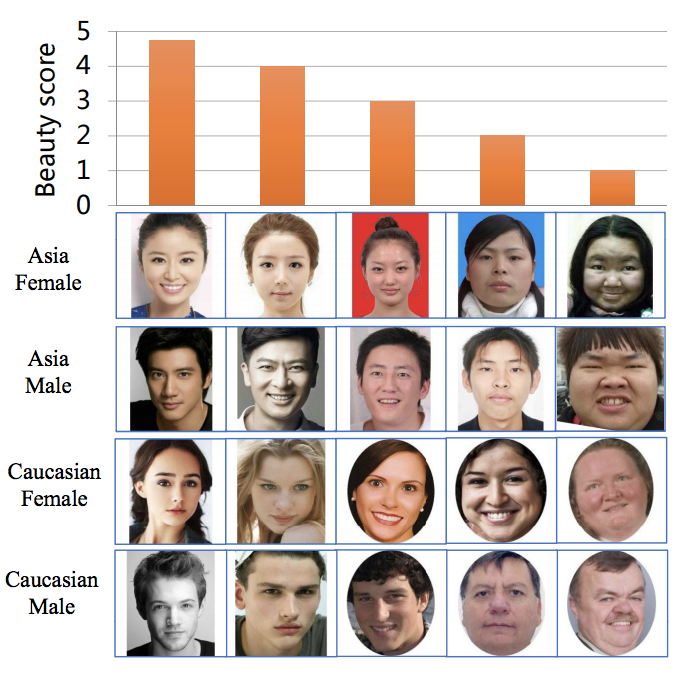


Research offers partial validation for these systems. Studies comparing AI scores to human ratings often report high correlation. Work from Stanford-affiliated researchers found alignment rates above ninety percent across large, diverse samples. Clinical studies using Pearson correlation coefficients also show strong agreement.
I approach these results carefully. Correlation does not mean objectivity. It means the AI mirrors dominant human preferences embedded in training data. The systems excel at reproducing consensus, not capturing individual taste.
As one computer vision researcher put it, “AI does not discover beauty. It compresses collective judgment into code.”
Strengths of Static Facial Analysis



AI attractiveness tests perform best with static attributes. Symmetry, proportional balance, and skin consistency are well suited to image analysis. In controlled conditions, the models deliver reliable rankings.
For professional use, this consistency has value. Designers testing avatar realism or researchers benchmarking synthetic faces benefit from objective repeatability. In these contexts, the score functions as a calibration tool rather than a personal verdict.
The technology works because it measures what it can see. Problems arise when users expect it to measure what it cannot.
Where AI Falls Short


Human attractiveness extends beyond geometry. Movement, voice, humor, and emotional presence shape real-world appeal. AI systems cannot capture these dimensions from a still image.
I have observed another limitation: score inflation. Many models skew slightly higher than human averages, possibly to avoid negative user reactions. This design choice improves engagement but reduces realism.
Cultural nuance also challenges these systems. Training data may be diverse, yet regional preferences remain underrepresented. As a result, some faces score differently than local human judgments would suggest.
Practical Uses Beyond Entertainment



Despite limitations, AI attractiveness tests serve practical purposes. Users compare profile photos for professional platforms. Developers validate synthetic avatars against aesthetic baselines. Researchers test biometric robustness.
In my own evaluations, these tools function best as comparative instruments. They help choose between images rather than define personal worth. Used this way, they add efficiency without psychological harm.
The risk emerges when numbers become identity markers instead of design aids.
Ethical and Social Implications



Ethically, the technology sits on sensitive ground. Beauty scoring can reinforce narrow standards and affect self-esteem. Transparency about limitations is essential.
I believe responsible platforms should emphasize context. Scores reflect algorithmic preferences, not universal truths. Clear messaging reduces misuse.
As sociologist Ruha Benjamin notes, “When algorithms judge people, the real danger lies in mistaking measurement for meaning.”
AI Attractiveness Tests in Research Contexts



Beyond consumer use, these systems support research. Synthetic face generation pipelines use attractiveness scoring to benchmark realism. Security teams test liveness detection against high scoring synthetic images.
In these environments, the technology contributes to measurable outcomes rather than personal evaluation. The distinction between research-grade and entertainment-grade use matters.
Takeaways
- AI attractiveness tests measure static facial geometry
- Scores correlate strongly with average human ratings
- Consistency makes them useful for comparison tasks
- Dynamic human traits remain outside AI scope
- Ethical framing determines social impact
- Best used as tools, not judgments
Conclusion
I see AI attractiveness tests as mirrors reflecting collective preference rather than arbiters of beauty. Their strength lies in consistency and speed. Their weakness lies in oversimplification. When users treat the output as playful feedback or technical reference, the technology serves a purpose. When treated as identity validation, it risks harm.
The broader lesson extends beyond beauty. As AI systems increasingly score human traits, society must decide how much authority to grant numbers. In that choice lies the difference between augmentation and reduction.
Read: Astrologer Bots and the New Age of AI-Driven Astrology
FAQs
What is an AI attractiveness test?
It is a computer vision tool that scores facial images based on learned patterns of symmetry and proportions.
Are the scores accurate?
They correlate strongly with average human ratings but remain subjective and limited.
Can AI judge real-world attractiveness?
No. It cannot assess personality, movement, or emotional presence.
Are these tools safe to use?
They are generally safe when used for comparison or curiosity, not self-worth evaluation.
Do different tools give different scores?
Yes. Models and training data vary across platforms.
References
Benjamin, R. (2019). Race after technology. Polity Press.
Rhodes, G. (2006). The evolutionary psychology of facial beauty. Annual Review of Psychology, 57, 199–226.
Zhang, K., et al. (2020). Facial attractiveness analysis with deep learning. IEEE Transactions on Affective Computing.

